Visual-Aware Speech Recognition for Noisy Scenarios
Abstract
Humans have the ability to utilize visual cues, such as lip movements and visual scenes, to enhance auditory perception, particularly in noisy environments. However, current Automatic Speech Recognition (ASR) or Audio-Visual Speech Recognition (AVSR) models often struggle in noisy scenarios. To solve this task, we propose a model that improves transcription by correlating noise sources to visual cues. Unlike works that rely on lip motion and require the speaker’s visibility, we exploit broader visual information from the environment. This allows our model to naturally filter speech from noise and improve transcription, much like humans do in noisy scenarios. Our method re-purposes pretrained speech and visual encoders, linking them with multi-headed attention. This approach enables the transcription of speech and the prediction of noise labels in video inputs. We introduce a scalable pipeline to develop audio-visual datasets, where visual cues correlate to noise in the audio. We show significant improvements over existing audio-only models in noisy scenarios. Results also highlight that visual cues play a vital role in improved transcription accuracy.
Dataset Pipeline and Qualitative Samples
To train our model for real-world scenarios, we combined labeled noise events from AudioSet with clean speech samples from PeopleSpeech. This fusion creates a diverse dataset that mirrors everyday acoustic environments, allowing the model to learn how to isolate relevant speech signals amid background noise.
Below is an example of a qualitative sample from our dataset that demonstrates the integration of environmental noise (skateboard) with clean speech from PeopleSpeech. This example highlights how the audio changes with different Signal-to-Noise Ratio (SNR) levels.
Video Example: Skateboard Noise
Clean Speech Example: PeopleSpeech
Audio Changes with Various SNR Levels
| SNR Level | Audio Sample |
|---|---|
| +20 dB | |
| +15 dB | |
| +10 dB | |
| +5 dB | |
| 0 dB | |
| -5 dB | |
| -10 dB | |
| -15 dB | |
| -20 dB |
Model Design
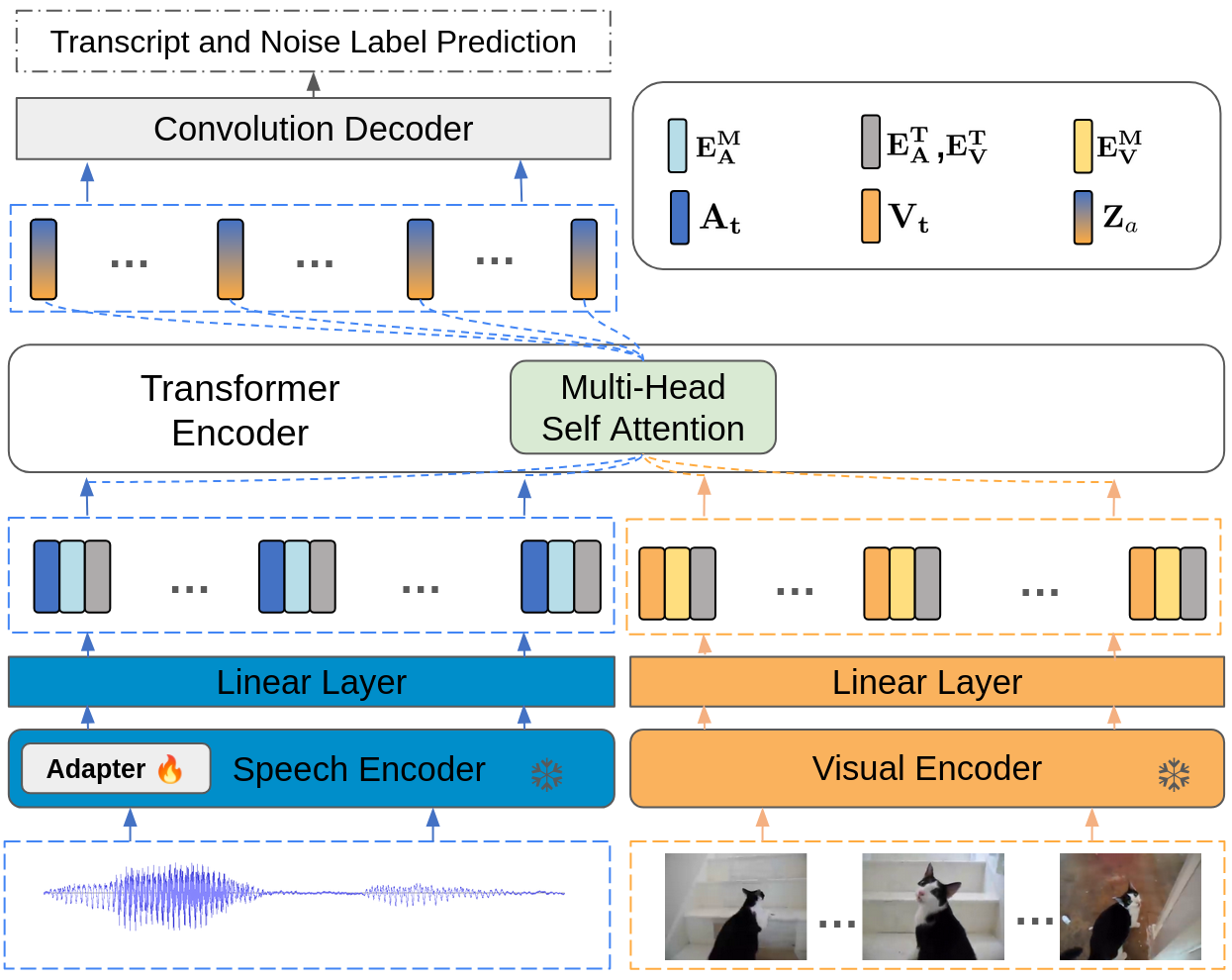
Visual cues in our environment significantly aid our understanding of auditory information—a phenomenon well-studied in cognitive psychology. Inspired by how humans can focus on relevant sounds even in noisy settings, I aimed to replicate this selective attention in speech recognition models. Traditional models, while effective in controlled environments, often fail to address the complexity of real-world audio scenarios. By integrating visual data, our model aims to pinpoint relevant auditory signals with higher accuracy.
Results
As shown in the results above, our proposed AV-SNR and AV-UNI-SNR models significantly outperform the baseline Conformer-CTC model across all SNR levels.
Conclusion
The integration of visual cues with audio signals in speech recognition systems has proven to significantly enhance transcription accuracy, particularly in noisy environments. By correlating noise sources with visual cues, our approach enables more accurate transcription and noise label prediction.
Acknowledgments
I would like to express my gratitude to the GSOC community, Red Hen Lab, CWRU-HPC and my mentor Karan Singla for their support throughout this project. I extend my sincere thanks to my advisor Prof. Makarand Tapaswi and Katha-AI Group at IIIT Hyderabad.